
Crawl Budget, po polsku określany budżetem indeksowania strony - to czas jaki Google poświęca na indeksowanie Twojej strony w danym dniu. Jest to limit podstron sprawdzanych przez boty Google zwane Googlebotami. Rozumienie crawl budget jako czasu, a nie liczby odpytywanych dziennie stron jest według nas lepsze i prościej go wtedy optymalizować. Nic nie stoi na przeszkodzie abyś nadal przeliczał to na podstrony.
Jak zachowuje się crawl budget?
I skąd u nas wzięła koncepcja rozpatrywania czasu jaki Google oddaje nam na crawling naszej strony?
W dużym uproszczeniu i patrząc na koncepcję z czasem indeksowanych stron, a nie ilością podstron to: jeżeli strona odpowiada szybko to limit sprawdzanych dziennie stron rośnie w górę, bo Google spędzą mniej czasu na każdej pojedynczej podstronie, jeżeli strona zwalnia to limit sprawdzanych stron spada. Jeżeli Twoja strona zwraca błędy limit odpytywanych nowych stron się zmniejsza, bo Google musi wracać do stron, które zwracały błędy, a same występowanie błędów wpływa na dzienne indeksowanie strony.
Musisz pamiętać, że Google ma skończoną liczbę zasobów i jeżeli masz dużą stronę to szczególnie musisz pamietać o optymalizacji. Nie oznacza to jednak, że każda strona ma podobny crawl budget, a Ty musisz się w nim zmieścić.
Crawl budget zależy też od ilości podstron jakie posiadasz oraz częstotliwości publikacji nowych treści. Inny crawl budget maja duże portale, inny portale o prawie nie zmieniającej się treści, jeszcze inny serwisy newsowe, które publikują codziennie po kilkadziesiąt newsów, które dodatkowo żyją i się zmieniają. W teorii najbardziej crawl budget-em powinny przejmować się złożone i duże portale internetowe, w praktyce może się zdarzyć, że mała strona będzie indeksowała duplikaty i crawl budget będzie marnowany albo przy nieoptymalnej architekturze treści Googleboty nigdy nie dotrą(albo dotrą w dopiero po długim czasie) do całości Twoich podstron.
Bardziej szczegółowo: crawl budget składa się z następujących składowych jakimi są crawl rate limit, crawl demand oraz crawl health, które wyjaśniamy poniżej.
Crawl rate limit
Crawl rate limit, czyli inaczej limit współczynnika indeksacji. Jest to współczynnik narzucający ilość żądań na sekundę, które Googlebot wysyła maksymalnie do Twojej strony podczas jej indeksowania. Crawl rate limit służy głównie do tego, aby Twoja witryna nie była spowolniana przez proces crawlingu. W Google Search Console można ograniczyć szybkości indeksowania przy problemach wydajnościowych. Jest to jednak najgorsza z możliwych dróg, nie rób tego nigdy, bo pamiętaj, że ustawienie wyższych limitów nie powoduje automatycznego zwiększenia indeksowania strony przez Google. Zoptymalizuj swoją stronę i serwery, nie używaj zmiany indeksacji, a tutaj płynnie przechodzimy do crawl health.
Crawl health
Crawl health – na "stan zdrowia crawla" wpływa szybkość odpowiadania i renderowania się strony oraz wszystkie błędy 5xx. Optymalizuj serwery jeżeli chcesz aby Twoja duża strona była szybko indeksowania. Szybkość stron to także czynnik rankingowy.
Crawl demand
Nawet jeżeli zadbasz o odpowiedni crawl health, Twoja strona będzie szybko odpowiadała, nie zwracała błędów podczas crawlingu, a wskaźniki w Lighthouse będą świeciły na zielono nie znaczy to, że będziesz wykorzystywał w 100% cały crawl limit. Dochodzi nam kolejne pojęcie jakim jest crawl demand, czyli popyt crawlowania.
Crawl demand - zależy od popularności contentu oraz aktualności content(pisania o czasie pod trendy) oraz od znudzenia Googlebota daną treścią, która się nie zmienia, czyli stallenless.
Wpływ tego wskaźnika znakomicie widzimy przy serwisach piszących pod Google News. Odpowiednia indeksacja stopniowo się rozwija gdy zaczynami pisać o danej tematyce.
Jak sprawdzić crawl budget na mojej stronie?
Ocenić na oko jak wygląda stan Twojego indeksowania możesz w GSC w zakładce Statystki indeksowania. Musisz tylko pamiętać, że jest krótki okres(3 miesiące) trzymany na wykresach przez Google oraz, że wykres zmienia się w przypadku crawlowanie przez Googlebot pod nowe algorytmy. Ten wykres nie jest niestety oparty o środowisko laboratoryjne.
 zrzut ekranu z Google Search Console | Gdzie są statystyki indeksowania?
zrzut ekranu z Google Search Console | Gdzie są statystyki indeksowania?
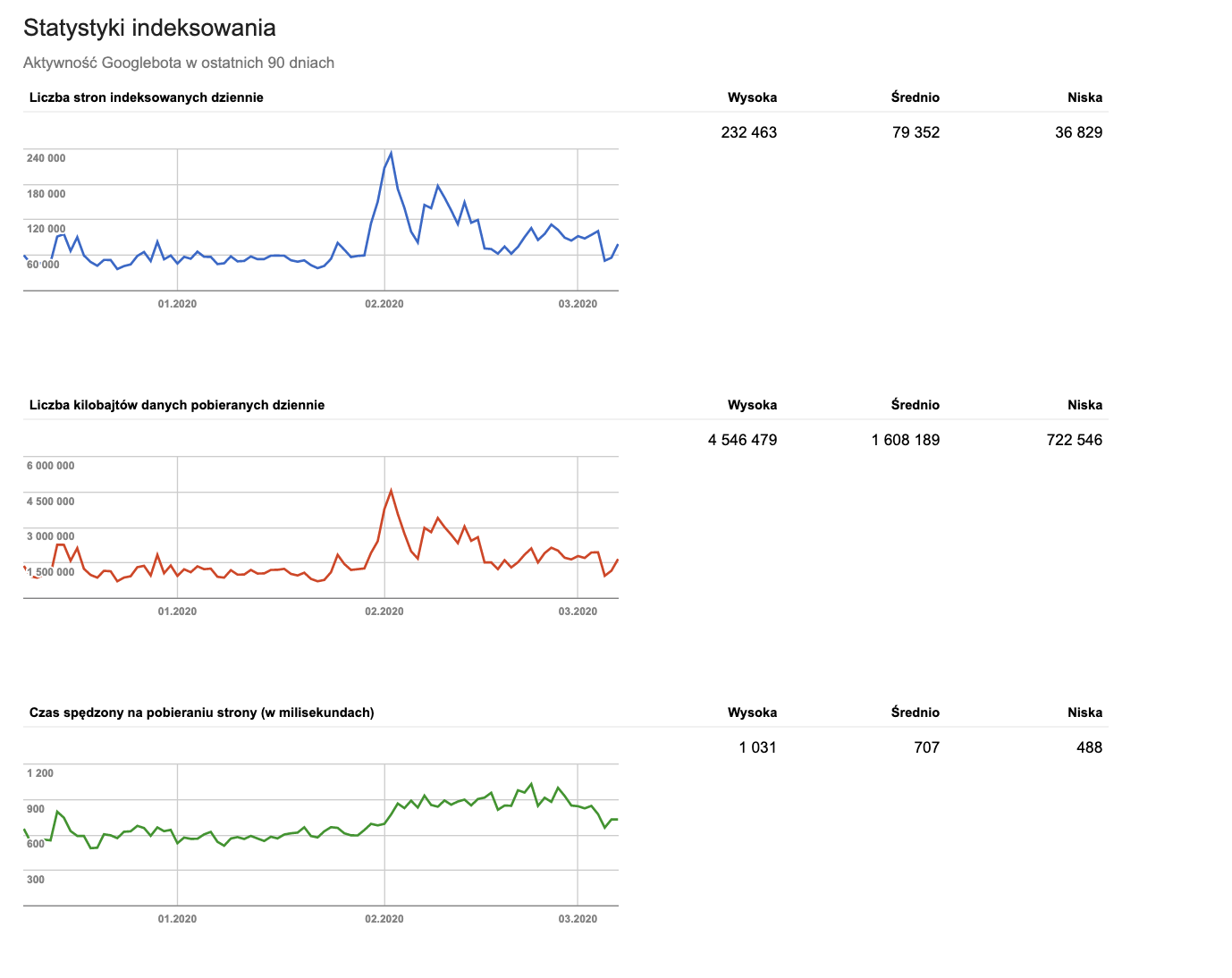 zrzut ekranu z Google Search Console | statystyki indeksowania
zrzut ekranu z Google Search Console | statystyki indeksowania
Jak audytować crawl budget?
My zaczynamy od analizy obecnych logów wciągając wszystkie historyczne access logi audytowanej strony i importujemy je do ELK. Dodatkowo analizujemy wszystkie zakładki Stan w GSC sprawdzając wszystkie próbki, które pokazuje nam Googlebot.
Szczegółowo przy analizie access logów - sprawdzamy strony po których chodzi Googlebot, a nie ma na nich ruchu, organicznego sprawdzamy statusy odpowiedzi szukając wielokrotnych przekierowań 3xx, stron błedów 4xx i statusów błędów serwera 5xx. Idealnie jak są logi z długiego okresu, da się je wtedy nałożyć na zmiany na stronie lub algorytmy Google.
Takie sam zabieg robimy crawlując stronę za pomocą Screaming Froga oraz własnego crawlera z maksymalnym crawl limitem na sekundę jaki ma Googlebot. Wykrywamy dzięki temu strony do których nie dotarło jeszcze Google oraz testujemy obciążenie strony przy specyficznym zachowaniu Googlebota.
Bo zebraniu danych grupujemy strony w: kategorie, artykuły, produkty inne oraz analizujemy jak chodzi po nich Googlebot. Zbieramy wszystkie dane ilościowe. Przypisujemy stroną odpowiedni poziom w hierarchii, oraz zaznaczamy money page. Dzięki takim analizą możemy wychwycić złe linkowanie wewnętrzne oraz złą architekturę informacji
Jak zwiększyć crawl budget?
Do optymalizacji crawl budget podchodzimy wielowymiarowo, zaczynając od technicznych rzeczy, które pokazujemy poniżej, kończąc na budowie odpowiedniej architektury informacji, która wykorzysta cały potencjał słów kluczowych w Twojej branży.
Techniczne aspekty na które trzeba zwrócić uwagę przy optymalizacji crawl budgetu i na które zwracamy my w naszych wytycznych SEO to:
- optymalizacja czasu ładowania każdej z rodzaju podstron za pomocą PageSpeed Insights oraz Lighthouse,
- optymalizacja duplikacji treści, czyli pokazywanie jednego adresu URL na jeden artykuł(On-site duplicate content),
- wprowadzenie odpowiedniej polityki linków kanonicznych, polityki robots.txt oraz noindex/nofollow,
- usuwanie parametrów z adresów URL i odpowiednie ustawienia tych parametrów w Google Search Console,
- eliminacja i nie zwracanie stron soft 404,
- nie pozwalanie na „nieskończoną przestrzeń”, czyli eliminacji miejsc w których bot może indeksować duplikaty w nieskończoność(np. niekończąca, zapętlająca się paginacja)
- poprawić linkowane wewnętrzne, żeby nie było orphan pages
Typowe problemy na stronach, które wpływają na crawl budget to:
- źle zaprojektowana nawigacja facetowa, a przez to przeważnie tworzący się iloczon kartezjański w adresowaniu z wszystkich wybieranych opcji w naszym ecomerce.
- zmienny identyfikator produktów w sklepie lub co częściej występuje w marketplace, gdzie produkty są importowane automatycznie i zmieniają się często
- identyfikator sesji w adresie strony - tak, to nadal się dzieje
- duża duplikacja treści lub duża parametryzacja i załatwianie wszystkiego linkiem kanonicznym





Współpracuj z nami!
Naszą mocą jest technologia i doświadczony zespółPrzez lata zdobywaliśmy doświadczenie u największych wydawców w Polsce, a teraz zadbamy o rozwój Twojej firmy od strategii wzrostu po wdrożenia na stronach dzięki naszemu własnemu software house'owi. Zaufaj nam, aby osiągać dobre wyniki.